2010
Yakun Sophia Shao, Judson Porter, Michael Lyons, Gu-Yeon Wei, and David Brooks. 7/2010. “
Power, Performance and Portability: System Design Considerations for Micro Air Vehicle Applications.” Sixth International Summer School on Advanced Computer Architecture and Compilation for Embedded Systems (ACACES).
Publisher's VersionAbstractRecent years have seen an increased interest in Micro Air Vehicles (MAVs) with applications ranging from search-and-rescue to mimicking insect behavior. MAVs have several challenging design requirements that impact processor design. These include real time processing demands and severe power/weight budgets. In this paper, we describe the characteristics of MAV applications and propose hardware acceleration to improve the power, performance, and portability of MAV system designs.
 Power, Performance and Portability: System Design Considerations for Micro Air Vehicle Applications
Power, Performance and Portability: System Design Considerations for Micro Air Vehicle Applications Xiaoyao Liang, David Brooks, and Gu Wei. 2/3/2010. “
Process variation tolerant circuit with voltage interpolation and variable latency.” United States of America.
Publisher's VersionAbstractA circuit having dynamically controllable power. The circuit comprises a plurality of pipelined stages, each of the pipelined stages comprising two clocking domains, a plurality of switching circuits, each switching circuit being connected to one of the pipelined stages, first and second power sources connected to each of the plurality of pipelined stages through the switching circuits, the first power source supplying a first voltage and the second power source supplying a second voltage, wherein the first and second power sources each may be applied to a pipelined stage independently of other pipelined stages, first and second complementary clocks, and a plurality of latches connected to the first and second complementary clocks and to the plurality of pipelined stages for proving latch-based clocking to control the first and second clocking domains and to enable time-borrowing across the plurality of switching circuits. The first voltage differs from the second voltage and the plurality of pipelined stages interpolates between the first and second voltages to provide differing effective voltages between the first and second voltages.
 Process variation tolerant circuit with voltage interpolation and variable latency
Process variation tolerant circuit with voltage interpolation and variable latency Michael Lyons, Mark Hempstead, Gu Wei, and David Brooks. 2/2010. “
The Accelerator Store framework for high-performance, low-power accelerator-based systems.” IEEE Computer Architecture Letters, 9, 2, Pp. 53-56.
Publisher's VersionAbstractHardware acceleration can increase performance and reduce energy consumption. To maximize these benefits, accelerator- based systems that emphasize computation on accelerators (rather than on general purpose cores) should be used. We introduce the “accelerator store,” a structure for sharing memory between accelerators in these accelerator-based systems. The accelerator store simplifies accelerator I/O and reduces area by mapping memory to accelerators when needed at runtime. Preliminary results demonstrate a 30% system area reduction with no energy overhead and less than 1% performance overhead in contrast to conventional DMA schemes.
The Accelerator Store framework for high-performance, low-power accelerator-based systems Vijay Reddi, Meeta Gupta, Glenn Holloway, Michael Smith, Gu Wei, and David Brooks. 1/2010. “
Predicting voltage droops using recurring program and microarchitectural event activity.” IEEE Micro, 30, 1.
Publisher's VersionAbstractShrinking feature size and diminishing supply voltage are making circuits more sensitive to supply voltage fluctuations within a microprocessor. If left unattended, voltage fluctuations can lead to timing violations or even transistor lifetime issues. A mechanism that dynamically learns to predict dangerous voltage fluctuations based on program and microarchitectural events can help steer the processor clear of danger.
Predicting voltage droops using recurring program and microarchitectural event activity 2009
Meeta Gupta, Jude Rivers, Pradip Bose, Gu Wei, and David Brooks. 12/12/2009. “
Tribeca: design for PVT variations with local recovery and fine-grained adaptation.” In 2009 42nd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Pp. 435–446. New York, NY, USA: IEEE.
Publisher's VersionAbstract
With continued advances in CMOS technology, parameter variations are emerging as a major design challenge. Irregularities during the fabrication of a microprocessor and variations of voltage and temperature during its operation widen worst-case timing margins of the design - degrading performance significantly. Because runtime variations like supply voltage droops and temperature fluctuations depend on the activity signature of the processor's workload, there are several opportunities to improve performance by dynamically adapting margins. This paper explores the power-performance efficiency gains that result from designing for typical conditions while dynamically tuning frequency and voltage to accommodate the runtime behavior of workloads. Such a design depends on a fail-safe mechanism that allows it to protect against margin violations during adaptation; we evaluate several such mechanisms, and we propose a local recovery scheme that exploits spatial variation among the units of the processor. While a processor designed for worst-case conditions might only be capable of a frequency that is 75% of an ideal processor with no parameter variations, we show that a fine-grained global frequency tuning mechanism improves power-performance efficiency (BIPS 3 /W) by 40% while operating at 91% of an ideal processor's frequency. Moreover, a per-unit voltage tuning mechanism aims to reduce the effect of within-die spatial variations to provide a 55% increase in power-performance efficiency. The benefits reported are clearly substantial in light of the <1% area overhead relative to existing global recovery mechanisms.
Kristen Lovin, Benjamin Lee, Xiaoyao Liang, David Brooks, and Gu Wei. 10/4/2009. “
Empirical performance models for 3T1D memories.” In ICCD'09: Proceedings of the 2009 IEEE international conference on Computer design, Pp. 398–403. IEEE.
AbstractProcess variation poses a threat to the performance and reliability of the 6T SRAM cell. Research has turned to new memory cell designs, such as the 3T1D DRAM cell, as potential replacement designs. If designers are to consider 3T1D memory architectures, performance models are needed to better understand memory cell behavior. We propose a decoupled approach for collecting Monte Carlo HSPICE data, reducing simulation times by simulating memory array components separately based on their contribution to the worst-case critical path. We use this Monte Carlo data to train regression models, which accurately predict retention and access times of a 3T1D memory array with a median error of 7.39%.
Empirical performance models for 3T1D memories Michael Lyons and David Brooks. 8/2009. “
The design of a bloom filter hardware accelerator for ultra low power systems.” In ISLPED '09: Proceedings of the 2009 ACM/IEEE international symposium on Low power electronics and design (ISLPED), Pp. 371–376https. ACM.
Publisher's VersionAbstractBattery-powered embedded systems require low energy usage to extend system lifetime. These systems must power many components for long periods of time and are particularly sensitive to energy use. Recent techniques for reducing energy consumption in wireless sensor networks, such as aggregation, require additional computation to reduce energy intensive radio transmissions. Larger demands on the processor will require more computational energy, but traditional energy reduction approaches, such as multi-core scaling with reduced frequency and voltage may prove heavy handed and ineffective for motes (sensor network nodes). Alternatively, application-specific hardware design (ASHD) architectures can reduce computational energy consumption by processing operations common to specific applications more efficiently than a general purpose processor. By the nature of their deeply embedded operation, motes support a limited set of applications, and thus the conventional general purpose computing paradigm may not be well-suited to mote operation. This paper examines the design considerations of a hardware accelerator for compressed Bloom filters, a data structure for efficiently storing set membership. We evaluate our ASHD design for three representative wireless sensor network applications and demonstrate that ASHD design reduces network latency by 59% and computational energy by 98%, showing the need for architecting processors for ASHD accelerators.
The design of a bloom filter hardware accelerator for ultra low power systems Vijay Reddi, Meeta Gupta, Michael Smith, Gu Wei, David Brooks, and Simone Campanoni. 7/26/2009. “
Software-assisted hardware reliability: abstracting circuit-level challenges to the software stack.” In 2009 46th ACM/IEEE Design Automation Conference, Pp. 788–793. San Francisco, CA: IEEE.
Publisher's VersionAbstractPower constrained designs are becoming increasingly sensitive to supply voltage noise. We propose a hardware-software collaborative approach to enable aggressive operating margins: a checkpoint-recovery mechanism corrects margin violations, while a run-time software layer reschedules the program's instruction stream to prevent recurring margin crossings at the same program location. The run-time layer removes 60% of these events with minimal overhead, thereby significantly improving overall performance.
Software-assisted hardware reliability: abstracting circuit-level challenges to the software stack Vijay Reddi, Meeta Gupta, Michael Smith, Gu Wei, David Brooks, and Simone Campanoni. 7/26/2009. “
Software-assisted hardware reliability: abstracting circuit-level challenges to the software stack.” In Proceedings of the 46th Annual Design Automation Conference, Pp. 788–793. San Francisco, CA.
Publisher's VersionAbstractPower constrained designs are becoming increasingly sensitive to supply voltage noise. We propose a hardware-software collaborative approach to enable aggressive operating margins: a checkpoint-recovery mechanism corrects margin violations, while a run-time software layer reschedules the program's instruction stream to prevent recurring margin crossings at the same program location. The run-time layer removes 60% of these events with minimal overhead, thereby significantly improving overall performance.
Software-assisted hardware reliability: abstracting circuit-level challenges to the software stack Krishna Rangan, Gu Wei, and David Brooks. 6/2009. “
Thread motion: fine-grained power management for multi-core systems.” In ACM SIGARCH Computer Architecture News, 3rd ed., 37: Pp. 302–313. ACM.
Publisher's VersionAbstract
Dynamic voltage and frequency scaling (DVFS) is a commonly-used power-management scheme that dynamically adjusts power and performance to the time-varying needs of running programs. Unfortunately, conventional DVFS, relying on off-chip regulators, faces limitations in terms of temporal granularity and high costs when considered for future multi-core systems. To overcome these challenges, this paper presents thread motion (TM), a fine-grained power-management scheme for chip multiprocessors (CMPs). Instead of incurring the high cost of changing the voltage and frequency of different cores, TM enables rapid movement of threads to adapt the time-varying computing needs of running applications to a mixture of cores with fixed but different power/performance levels. Results show that for the same power budget, two voltage/frequency levels are sufficient to provide performance gains commensurate to idealized scenarios using per-core voltage control. Thread motion extends workload-based power management into the nanosecond realm and, for a given power budget, provides up to 20% better performance than coarse-grained DVFS.
Meeta Gupta, Vijay Reddi, Glenn Holloway, Gu Wei, and David Brooks. 4/20/2009. “
An event-guided approach to reducing voltage noise in processors.” In Design, Automation & Test in Europe Conference & Exhibition, 4/20/2009. DATE'09., Pp. 160–165. Nice, France: IEEE.
Publisher's Version An event-guided approach to reducing voltage noise in processors Kevin Brownell, Ali Khan, David Brooks, and Gu Wei. 3/16/2009. “
Place and route considerations for voltage interpolated designs.” In Quality of Electronic Design, 3/16/2009. ISQED 3/16/2009. Quality Electronic Design, Pp. 594–600. IEEE.
Publisher's VersionAbstract
Voltage interpolation is a promising post fabrication technique for combating the effects of process variations. The benefits of voltage interpolation are well understood. Its implementation in a VLSI-CAD flow has been considered through the synthesis stage. In this paper we study the implications of place and route on voltage interpolation. We evaluate multiple placement strategies, and conclude that a hybridization of forced placement and cluster boxing techniques results in minimum overhead.
Lukasz Strozek and David Brooks. 3/2009. “
Energy-and area-efficient architectures through application clustering and architectural heterogeneity.” ACM Transactions on Architecture and Code Optimization (TACO), 6, 1, Pp. 4.
Publisher's VersionAbstract
Customizing architectures for particular applications is a promising approach to yield highly energy-efficient designs for embedded systems. This work explores the benefits of architectural customization for a class of embedded architectures typically used in energy- and area-constrained application domains, such as sensor nodes and multimedia processing. We implement a process flow that performs an automatic synthesis and evaluation of the different architectures based on runtime profiles of applications and determines an efficient architecture, with consideration for both energy and area constraints. An expressive architectural model, used by our engine, is introduced that takes advantage of efficient opcode allocation, several memory addressing modes, and operand types. By profiling embedded benchmarks from a variety of sensor and multimedia applications, we show that the energy savings resulting from various architectural optimizations relative to the base architectures (e.g., MIPS and MSP430) are significant and can reach 50%, depending on the application. We then identify the set of architectures that achieves near-optimal savings for a group of applications. Finally, we propose the use of heterogeneous ISA processors implementing those architectures as a solution to capitalize on energy savings provided by application customization while executing a range of applications efficiently.
Vijay Reddi, Meeta Gupta, Glenn Holloway, Michael Smith, Gu-Yeon Wei, and David Brooks. 2/14/2009. “
Voltage emergency prediction: Using Signatures to Reduce Operating Margins.” In 2009 IEEE 15th International Symposium on High Performance Computer Architecture.
Publisher's VersionAbstract
Inductive noise forces microprocessor designers to sacrifice performance in order to ensure correct and reliable operation of their designs. The possibility of wide fluctuations in supply voltage means that timing margins throughout the processor must be set pessimistically to protect against worst-case droops and surges. While sensor-based reactive schemes have been proposed to deal with voltage noise, inherent sensor delays limit their effectiveness. Instead, this paper describes a voltage emergency predictor that learns the signatures of voltage emergencies (the combinations of control flow and microarchitectural events leading up to them) and uses these signatures to prevent recurrence of the corresponding emergencies. In simulations of a representative superscalar microprocessor in which fluctuations beyond 4% of nominal voltage are treated as emergencies (an aggressive configuration), these signatures can pinpoint the likelihood of an emergency some 16 cycles ahead of time with 90% accuracy. This lead time allows machines to operate with much tighter voltage margins (4% instead of 13%) and up to 13.5% higher performance, which closely approaches the 14.2% performance improvement possible with an ideal oracle-based predictor.
Vijay Reddi, Meeta Gupta, Glenn Holloway, Gu Wei, Michael Smith, and David Brooks. 2/14/2009. “
Voltage emergency prediction: Using signatures to reduce operating margins.” In 2009 IEEE 15th International Symposium on High Performance Computer Architecture, Pp. 18–29. Raleigh, NC, USA: IEEE.
Publisher's VersionAbstractInductive noise forces microprocessor designers to sacrifice performance in order to ensure correct and reliable operation of their designs. The possibility of wide fluctuations in supply voltage means that timing margins throughout the processor must be set pessimistically to protect against worst-case droops and surges. While sensor-based reactive schemes have been proposed to deal with voltage noise, inherent sensor delays limit their effectiveness. Instead, this paper describes a voltage emergency predictor that learns the signatures of voltage emergencies (the combinations of control flow and microarchitectural events leading up to them) and uses these signatures to prevent recurrence of the corresponding emergencies. In simulations of a representative superscalar microprocessor in which fluctuations beyond 4% of nominal voltage are treated as emergencies (an aggressive configuration), these signatures can pinpoint the likelihood of an emergency some 16 cycles ahead of time with 90% accuracy. This lead time allows machines to operate with much tighter voltage margins (4% instead of 13%) and up to 13.5% higher performance, which closely approaches the 14.2% performance improvement possible with an ideal oracle-based predictor.
Voltage emergency prediction: Using signatures to reduce operating margins Vijay Reddi, Meeta Gupta, Krishna Rangan, Simone Campanoni, Glenn Holloway, Michael Smith, Gu Wei, and David Brooks. 1/2009. “
Voltage noise: Why it’s bad, and what to do about it.” 5th IEEE Workshop on Silicon Errors in Logic-System Effects (SELSE), Palo Alto, CA.
AbstractPower constrained designs are becoming increasingly sensitive to supply voltage noise. We propose hardware-software collaboration to enable aggressive voltage margins: a fail-safe hardware mechanism tolerates margin violations in order to train a run-time software layer that reschedules instructions to avoid recurring violations. Additionally, the software controls an emergency signature-based predictor that throttles to suppress emergencies that code rescheduling cannot eliminate.
Voltage noise: Why it’s bad, and what to do about it Xiaoyao Liang, Benjamin Lee, Gu Wei, and David Brooks. 2009. “
Design and test strategies for microarchitectural post-fabrication tuning.” In Computer Design, 2009. ICCD 2009. IEEE International Conference on, Pp. 84–90. IEEE.
Publisher's VersionAbstractProcess variations are a major hurdle for continued technology scaling. Both systematic and random variations will affect the critical delay of fabricated chips, causing a wide frequency and power distribution. Tuning techniques adapt the microarchitecture to mitigate the impact of variations at post-fabrication testing time. This paper proposes a new post-fabrication testing framework that accounts for testing costs. This framework uses on-chip canary circuits to capture systematic variation while using statistical analysis to estimate random variation. We derive regression models to predict chip performance and power. These techniques comprise an integrated framework that identifies the most energy efficient post-fabrication tuning configuration for each chip.
Design and test strategies for microarchitectural post-fabrication tuning Lukasz Strozek and David Brooks. 2009. “
Efficient architectures through application clustering and heterogeneity.” In CASES '06: Proceedings of the 2006 international conference on Compilers, architecture and synthesis for embedded systems, Pp. 190–200. Citeseer.
Publisher's VersionAbstract
Customizing architectures for particular applications is a promising approach to yield highly energy-efficient designs for embedded systems. This work explores the benefits of architectural customization for a class of embedded architectures typically used in energy-constrained application domains such as sensor node and multimedia processing. We implement a process flow that analyzes runtime profiles of applications and combines this information with a model for our architectural design space providing a robust customization engine built upon a fully automated method for determining an efficient architecture (together with appropriate application transformations). By profiling embedded benchmarks from a variety of sensor and multimedia applications, the paper shows the relative energy savings resulting from various architectural optimizations and identifies the number of architectures that achieves near-optimal savings for a group of applications. This paper proposes the use of heterogeneous chip-multiprocessors as a cost-effective approach to capitalize on the potential energy savings provided by application customization while executing a range of applications efficiently.
Mark Hempstead, Gu Wei, and David Brooks. 2009. “
Navigo: An early-stage model to study power-contrained architectures and specialization.” Workshop on Modeling, Benchmarking, and Simulation.
AbstractAs the number of transistors double, it becomes difficult to power all of them within a strict power budget and still achieve the performance gains of that the industry has achieved historically. This work presents, Navigo, a modeling framework for architecture exploration across future process technology generations. The model includes support for voltage and frequency scaling based on ITRS and PTM models. This work is designed to aid architects in the planning stages of next generation microprocessors, by addressing the space between early-stage back-of-the-envelope calculations and later stage cycle accurate simulators. Using parameters from existing commercial processor cores, we show how power consumption limits the theoretical throughput of future processors. Navigo shows that specialization is the answer to circumvent the power density limit that curbs performance gains and resume traditional 1.58x performance growth trends. We present analysis, using next generation of process technologies, that shows the fraction of area that must be allocated for specialization to maintain performance growth must increase with each new generation of process technology.
Navigo: An early-stage model to study power-contrained architectures and specialization 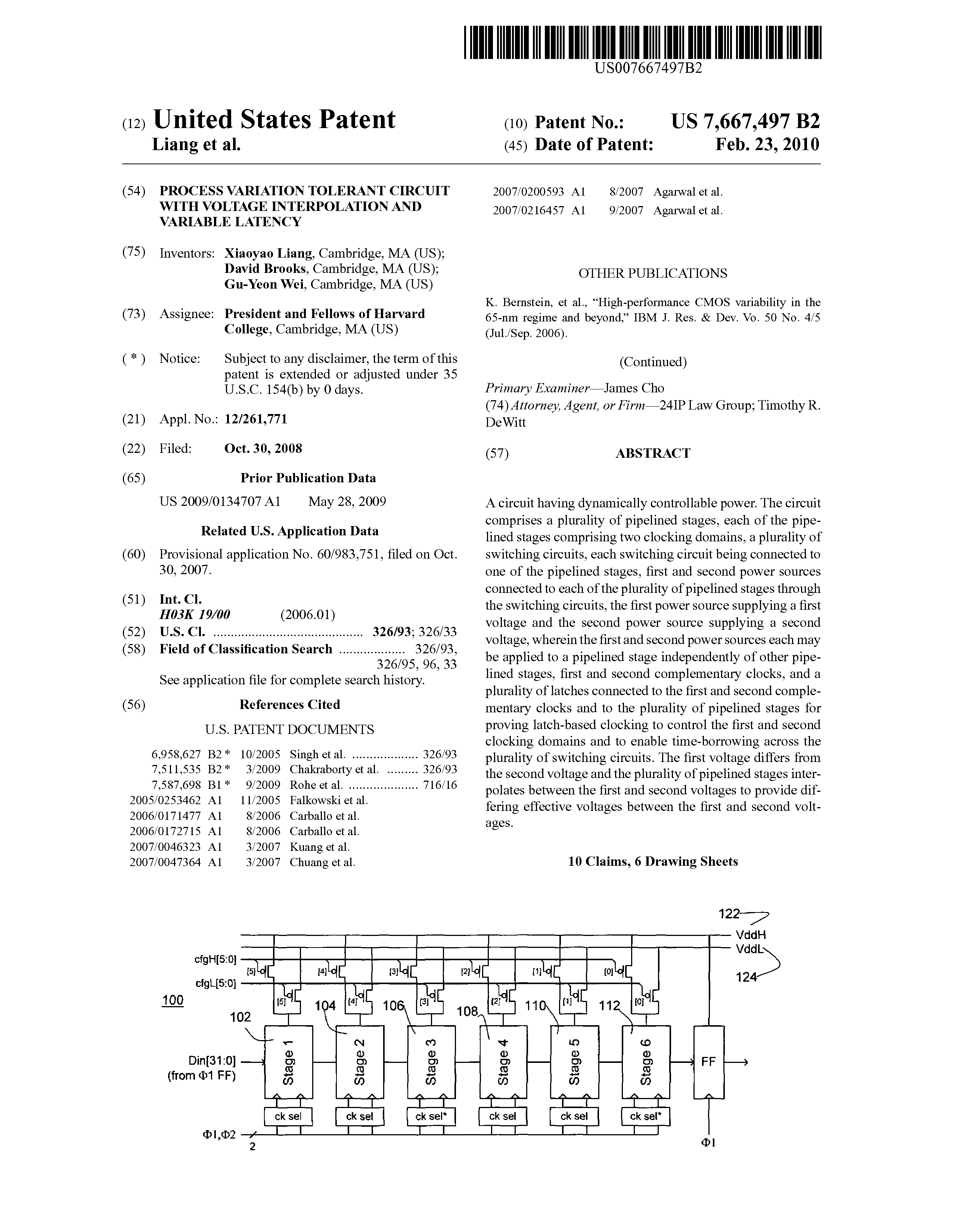{kind=link}