2011
David Brooks. 1/25/2011. “
The alarms project: a hardware/software approach to addressing parameter variations.” In Design Automation Conference (ASP-DAC), 2011 16th Asia and South Pacific, Pp. 291–291. IEEE.
Publisher's VersionAbstractParameter variations (process, voltage, and temperature) threaten continued performance scaling of power-constrained computer systems. As designers seek to contain the power consumption of microprocessors through reductions in supply voltage and power-saving techniques such as clock-gating, these systems suffer increasingly large power supply fluctuations due to the finite impedance of the power supply network. These supply fluctuations, referred to as voltage emergencies, must be managed to guarantee correctness. Traditional approaches to address this problem incur high-cost or compromise power/performance efficiency. Our research seeks ways to handle these alarm conditions through a combined hardware/software approach, motivated by root cause analysis of voltage emergencies revealing that many of these events are heavily linked to both program control flow and microarchitectural events (cache misses and pipeline flushes). This talk will discuss three aspects of the project: (1) a fail-safe mechanism that provides hardware guaranteed correctness; (2) a voltage emergency predictor that leverages control flow and microarchitectural event information to predict voltage emergencies up to 16 cycles in advance; and (3) a proof-of-concept dynamic compiler implementation that demonstrates that dynamic code transformations can be used to eliminate voltage emergencies from the instruction stream with minimal impact on performance [1–9].
 The alarms project: a hardware/software approach to addressing parameter variations
The alarms project: a hardware/software approach to addressing parameter variations Vijay Reddi, Svilen Kanev, Wonyoung Kim, Simone Campanoni, Michael Smith, Gu Wei, and David Brooks. 1/2011. “
Voltage Noise in Production Processors.” IEEE Micro, 31, 1.
Publisher's VersionAbstractVoltage variations are a major challenge in processor design. Here, researchers characterize the voltage noise characteristics of programs as they run to completion on a production Core 2 Duo processor. Furthermore, they characterize the implications of resilient architecture design for voltage variation in future systems.
Voltage Noise in Production Processors 2010
Vijay Reddi, Svilen Kanev, Wonyoung Kim, Simone Campanoni, Michael Smith, Gu Wei, and David Brooks. 12/4/2010. “
Voltage smoothing: Characterizing and mitigating voltage noise in production processors via software-guided thread scheduling.” In 2010 43rd Annual IEEE/ACM International Symposium on Microarchitecture. IEEE.
Publisher's VersionAbstractParameter variations have become a dominant challenge in microprocessor design. Voltage variation is especially daunting because it happens so rapidly. We measure and characterize voltage variation in a running Intel Core2 Duo processor. By sensing on-die voltage as the processor runs single-threaded, multi-threaded, and multi-program workloads, we determine the average supply voltage swing of the processor to be only 4%, far from the processor’s 14% worst-case operating voltage margin. While such large margins guarantee correctness, they penalize performance and power efficiency. We investigate and quantify the benefits of designing a processor for typical-case (rather than worst-case) voltage swings, assuming that a fail-safe mechanism protects it from infrequently occurring large voltage fluctuations. With today’s processors, such resilient designs could yield 15% to 20% performance improvements. But we also show that in future systems, these gains could be lost as increasing voltage swings intensify the frequency of fail-safe recoveries. After characterizing microarchitectural activity that leads to voltage swings within multi-core systems, we show that a voltage-noise-aware thread scheduler in software can co-schedule phases of different programs to mitigate error recovery overheads in future resilient processor designs.
Voltage smoothing: Characterizing and mitigating voltage noise in production processors via software-guided thread scheduling Karpelson Michael, Whitney P, Gu Wei, and Wood J. 10/18/2010. “
Energetics of flapping-wing robotic insects: towards autonomous hovering flight.” In 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, Pp. 1630–1637. IEEE.
Publisher's VersionAbstractFlapping-wing mechanisms inspired by biological insects have the potential to enable a new class of small, highly maneuverable aerial robots with hovering capabilities. In order for such devices to operate without an external power source, it is necessary to address a complex system design challenge: the integration of all of the required components on board the robot. This paper discusses the flight energetics of flapping-wing robotic insects with the goal of selecting design parameters that enable power autonomy and maximize flight time. The subsystems of the robot are analyzed both from a broad perspective and using a detailed set of models for a piezoelectrically driven two-wing design. The models are used to perform a system-level optimization for the maximum flight time permitted by current technology, compare the resulting robot configurations to biological insects across several key metrics, and discuss the effect of performance gains in various subsystems of the robot.
Energetics of flapping-wing robotic insects: towards autonomous hovering flight Benjamin Lee and David Brooks. 9/2010. “
Applied inference: Case studies in microarchitectural design.” ACM Transactions on Architecture and Code Optimization (TACO), 7, 2, Pp. 8.
Publisher's VersionAbstract
We propose and apply a new simulation paradigm for microarchitectural design evaluation and optimization. This paradigm enables more comprehensive design studies by combining spatial sampling and statistical inference. Specifically, this paradigm (i) defines a large, comprehensive design space, (ii) samples points from the space for simulation, and (iii) constructs regression models based on sparse simulations. This approach greatly improves the computational efficiency of microarchitectural simulation and enables new capabilities in design space exploration.
We illustrate new capabilities in three case studies for a large design space of approximately 260,000 points: (i) Pareto frontier, (ii) pipeline depth, and (iii) multiprocessor heterogeneity analyses. In particular, regression models are exhaustively evaluated to identify Pareto optimal designs that maximize performance for given power budgets. These models enable pipeline depth studies in which all parameters vary simultaneously with depth, thereby more effectively revealing interactions with nondepth parameters. Heterogeneity analysis combines regression-based optimization with clustering heuristics to identify efficient design compromises between similar optimal architectures. These compromises are potential core designs in a heterogeneous multicore architecture. Increasing heterogeneity can improve bips3/w efficiency by as much as 2.4×, a theoretical upper bound on heterogeneity benefits that neglects contention between shared resources as well as design complexity. Collectively these studies demonstrate regression models' ability to expose trends and identify optima in diverse design regions, motivating the application of such models in statistical inference for more effective use of modern simulator infrastructure.
Vijay Reddi, Simone Campanoni, Meeta Gupta, Michael Smith, Gu Wei, David Brooks, and Kim Hazelwood. 9/2010. “
Eliminating voltage emergencies via software-guided code transformations.” ACM Transactions on Architecture and Code Optimization (TACO), 7, 2, Pp. 1-28.
Publisher's VersionAbstractIn recent years, circuit reliability in modern high-performance processors has become increasingly important. Shrinking feature sizes and diminishing supply voltages have made circuits more sensitive to microprocessor supply voltage fluctuations. These fluctuations result from the natural variation of processor activity as workloads execute, but when left unattended, these voltage fluctuations can lead to timing violations or even transistor lifetime issues. In this paper, we present a hardware-software collaborative approach to mitigate voltage fluctuations. A checkpoint-recovery mechanism rectifies errors when voltage violates maximum tolerance settings, while a run-time software layer reschedules the program’s instruction stream to prevent recurring violations at the same program location. The run-time layer, combined with the proposed code rescheduling algorithm, removes 60% of all violations with minimal overhead, thereby significantly improving overall performance. Our solution is a radical departure from the ongoing industry standard approach to circumvent the issue altogether by optimizing for the worst case voltage flux, which compromises power and performance efficiency severely, especially looking ahead to future technology generations. Existing conservative approaches will have severe implications on the ability to deliver efficient microprocessors. The proposed technique reassembles a traditional reliability problem as a runtime performance optimization problem, thus allowing us to design processors for typical case operation by building intelligent algorithms that can prevent recurring violations.
Eliminating voltage emergencies via software-guided code transformations Benton Calhoun and David Brooks. 7/2010. “
Can Subthreshold and Near-Threshold Circuits Go Mainstream?” Micro, IEEE, 30, 4, Pp. 80–85.
Publisher's VersionAbstractRecent research has shown the potential benefits of subthreshold or near-threshold operation, which gives up a substantial degree of speed in order to reduce energy per operation. This is an excellent trade-off for many tasks, such as cyberphysical systems. This prolegomenon summarizes the benefits and challenges of subthreshold or near-threshold operation.
Can Subthreshold and Near-Threshold Circuits Go Mainstream? Yakun Sophia Shao, Judson Porter, Michael Lyons, Gu-Yeon Wei, and David Brooks. 7/2010. “
Power, Performance and Portability: System Design Considerations for Micro Air Vehicle Applications.” Sixth International Summer School on Advanced Computer Architecture and Compilation for Embedded Systems (ACACES).
Publisher's VersionAbstractRecent years have seen an increased interest in Micro Air Vehicles (MAVs) with applications ranging from search-and-rescue to mimicking insect behavior. MAVs have several challenging design requirements that impact processor design. These include real time processing demands and severe power/weight budgets. In this paper, we describe the characteristics of MAV applications and propose hardware acceleration to improve the power, performance, and portability of MAV system designs.
Power, Performance and Portability: System Design Considerations for Micro Air Vehicle Applications Xiaoyao Liang, David Brooks, and Gu Wei. 2/3/2010. “
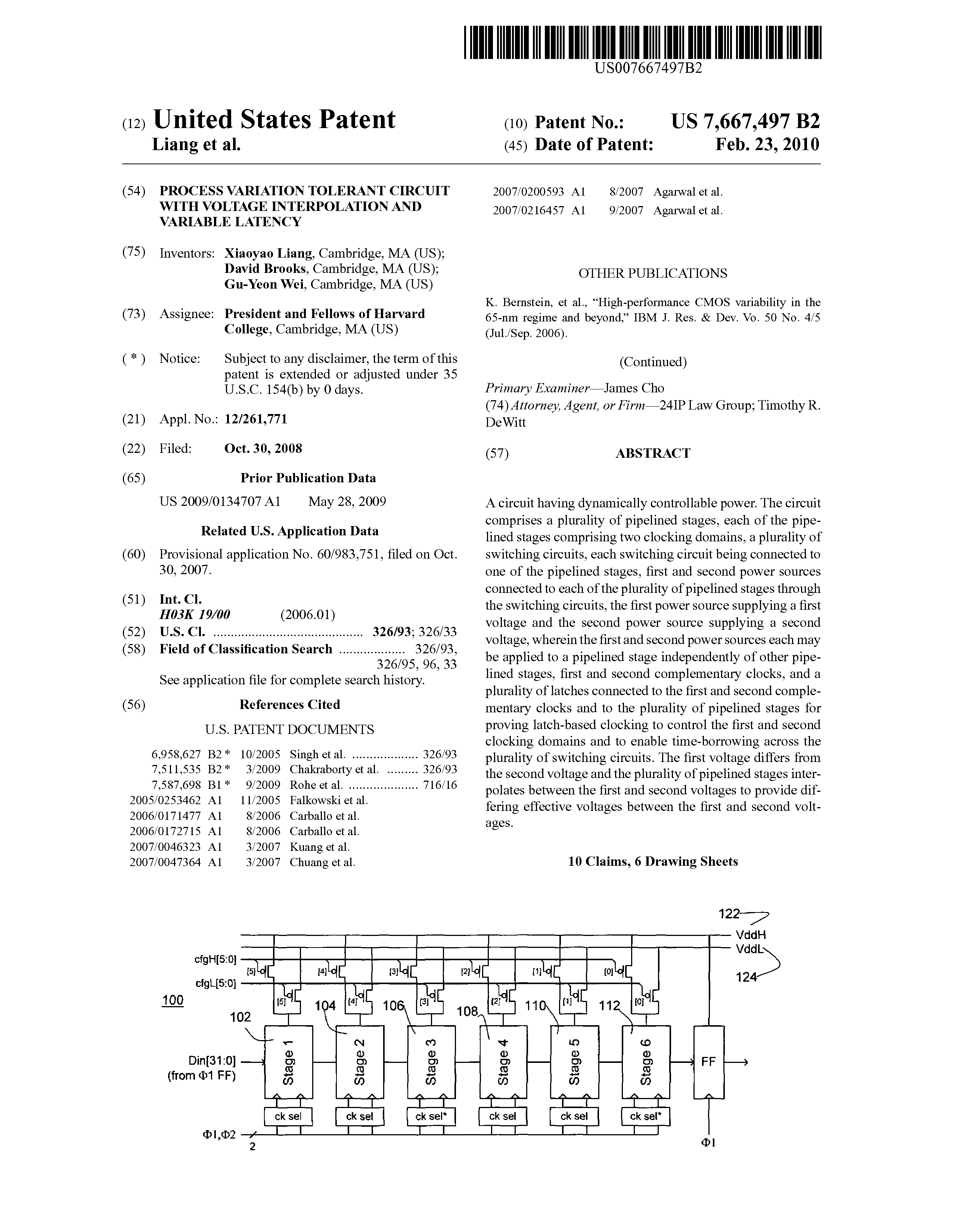
Process variation tolerant circuit with voltage interpolation and variable latency.” United States of America.
Publisher's VersionAbstractA circuit having dynamically controllable power. The circuit comprises a plurality of pipelined stages, each of the pipelined stages comprising two clocking domains, a plurality of switching circuits, each switching circuit being connected to one of the pipelined stages, first and second power sources connected to each of the plurality of pipelined stages through the switching circuits, the first power source supplying a first voltage and the second power source supplying a second voltage, wherein the first and second power sources each may be applied to a pipelined stage independently of other pipelined stages, first and second complementary clocks, and a plurality of latches connected to the first and second complementary clocks and to the plurality of pipelined stages for proving latch-based clocking to control the first and second clocking domains and to enable time-borrowing across the plurality of switching circuits. The first voltage differs from the second voltage and the plurality of pipelined stages interpolates between the first and second voltages to provide differing effective voltages between the first and second voltages.
 Process variation tolerant circuit with voltage interpolation and variable latency
Process variation tolerant circuit with voltage interpolation and variable latency Michael Lyons, Mark Hempstead, Gu Wei, and David Brooks. 2/2010. “
The Accelerator Store framework for high-performance, low-power accelerator-based systems.” IEEE Computer Architecture Letters, 9, 2, Pp. 53-56.
Publisher's VersionAbstractHardware acceleration can increase performance and reduce energy consumption. To maximize these benefits, accelerator- based systems that emphasize computation on accelerators (rather than on general purpose cores) should be used. We introduce the “accelerator store,” a structure for sharing memory between accelerators in these accelerator-based systems. The accelerator store simplifies accelerator I/O and reduces area by mapping memory to accelerators when needed at runtime. Preliminary results demonstrate a 30% system area reduction with no energy overhead and less than 1% performance overhead in contrast to conventional DMA schemes.
The Accelerator Store framework for high-performance, low-power accelerator-based systems Vijay Reddi, Meeta Gupta, Glenn Holloway, Michael Smith, Gu Wei, and David Brooks. 1/2010. “
Predicting voltage droops using recurring program and microarchitectural event activity.” IEEE Micro, 30, 1.
Publisher's VersionAbstractShrinking feature size and diminishing supply voltage are making circuits more sensitive to supply voltage fluctuations within a microprocessor. If left unattended, voltage fluctuations can lead to timing violations or even transistor lifetime issues. A mechanism that dynamically learns to predict dangerous voltage fluctuations based on program and microarchitectural events can help steer the processor clear of danger.
Predicting voltage droops using recurring program and microarchitectural event activity 2009
Meeta Gupta, Jude Rivers, Pradip Bose, Gu Wei, and David Brooks. 12/12/2009. “
Tribeca: design for PVT variations with local recovery and fine-grained adaptation.” In 2009 42nd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Pp. 435–446. New York, NY, USA: IEEE.
Publisher's VersionAbstract
With continued advances in CMOS technology, parameter variations are emerging as a major design challenge. Irregularities during the fabrication of a microprocessor and variations of voltage and temperature during its operation widen worst-case timing margins of the design - degrading performance significantly. Because runtime variations like supply voltage droops and temperature fluctuations depend on the activity signature of the processor's workload, there are several opportunities to improve performance by dynamically adapting margins. This paper explores the power-performance efficiency gains that result from designing for typical conditions while dynamically tuning frequency and voltage to accommodate the runtime behavior of workloads. Such a design depends on a fail-safe mechanism that allows it to protect against margin violations during adaptation; we evaluate several such mechanisms, and we propose a local recovery scheme that exploits spatial variation among the units of the processor. While a processor designed for worst-case conditions might only be capable of a frequency that is 75% of an ideal processor with no parameter variations, we show that a fine-grained global frequency tuning mechanism improves power-performance efficiency (BIPS 3 /W) by 40% while operating at 91% of an ideal processor's frequency. Moreover, a per-unit voltage tuning mechanism aims to reduce the effect of within-die spatial variations to provide a 55% increase in power-performance efficiency. The benefits reported are clearly substantial in light of the <1% area overhead relative to existing global recovery mechanisms.
Kristen Lovin, Benjamin Lee, Xiaoyao Liang, David Brooks, and Gu Wei. 10/4/2009. “
Empirical performance models for 3T1D memories.” In ICCD'09: Proceedings of the 2009 IEEE international conference on Computer design, Pp. 398–403. IEEE.
AbstractProcess variation poses a threat to the performance and reliability of the 6T SRAM cell. Research has turned to new memory cell designs, such as the 3T1D DRAM cell, as potential replacement designs. If designers are to consider 3T1D memory architectures, performance models are needed to better understand memory cell behavior. We propose a decoupled approach for collecting Monte Carlo HSPICE data, reducing simulation times by simulating memory array components separately based on their contribution to the worst-case critical path. We use this Monte Carlo data to train regression models, which accurately predict retention and access times of a 3T1D memory array with a median error of 7.39%.
Empirical performance models for 3T1D memories Chung Hayun and Gu Wei. 9/13/2009. “
Design-space exploration of backplane receivers with high-speed ADCs and digital equalization.” In 2009 IEEE Custom Integrated Circuits Conference, Pp. 555–558. IEEE.
Publisher's VersionAbstractHigh-speed backplane receivers based on front-end ADCs with digital equalization facilitate design reuse, portability, and flexibility to reconfigure itself and accommodate different channel environments. However, power and complexity of such receivers can be high and require thorough high-level exploration to optimize design tradeoffs. This paper presents a backplane receiver model consisting of a simple, accurate, experimentally-verified, and parameterized high-speed flash ADC and a configurable digital equalizer for design-space exploration. Simulations demonstrate tradeoffs between ADC and equalizer bit resolution while maintaining constant receiver performance.
Design-space exploration of backplane receivers with high-speed ADCs and digital equalization Ankur Agrawal, Andrew Liu, Pavan Kumar Hanumolu, and Gu-Yeon Wei. 8/2009. “
An 8$, times, $5 Gb/s Parallel Receiver With Collaborative Timing Recovery.” IEEE Journal of Solid-State Circuits, 44, 11, Pp. 3120–3130.
Publisher's VersionAbstractThis paper presents the design of an 8 channel, 5 & Gb/s per channel parallel receiver with collaborative timing recovery and no forwarded clock. The receiver architecture exploits synchrony in the transmitted data streams in a parallel interface and combines error information from multiple phase detectors in the receiver to produce one global synthesized clock. This collaborative timing recovery scheme enables wideband jitter tracking without increasing the dithering jitter in the synthesized clock. Circuit design techniques employed to implement this receiver architecture are discussed. Experimental results from a 130 nm CMOS test chip demonstrate the enhanced tracking bandwidth and lower dithering jitter of the recovered clock.
An 8$, times, $5 Gb/s Parallel Receiver With Collaborative Timing Recovery Michael Lyons and David Brooks. 8/2009. “
The design of a bloom filter hardware accelerator for ultra low power systems.” In ISLPED '09: Proceedings of the 2009 ACM/IEEE international symposium on Low power electronics and design (ISLPED), Pp. 371–376https. ACM.
Publisher's VersionAbstractBattery-powered embedded systems require low energy usage to extend system lifetime. These systems must power many components for long periods of time and are particularly sensitive to energy use. Recent techniques for reducing energy consumption in wireless sensor networks, such as aggregation, require additional computation to reduce energy intensive radio transmissions. Larger demands on the processor will require more computational energy, but traditional energy reduction approaches, such as multi-core scaling with reduced frequency and voltage may prove heavy handed and ineffective for motes (sensor network nodes). Alternatively, application-specific hardware design (ASHD) architectures can reduce computational energy consumption by processing operations common to specific applications more efficiently than a general purpose processor. By the nature of their deeply embedded operation, motes support a limited set of applications, and thus the conventional general purpose computing paradigm may not be well-suited to mote operation. This paper examines the design considerations of a hardware accelerator for compressed Bloom filters, a data structure for efficiently storing set membership. We evaluate our ASHD design for three representative wireless sensor network applications and demonstrate that ASHD design reduces network latency by 59% and computational energy by 98%, showing the need for architecting processors for ASHD accelerators.
The design of a bloom filter hardware accelerator for ultra low power systems Vijay Reddi, Meeta Gupta, Michael Smith, Gu Wei, David Brooks, and Simone Campanoni. 7/26/2009. “
Software-assisted hardware reliability: abstracting circuit-level challenges to the software stack.” In 2009 46th ACM/IEEE Design Automation Conference, Pp. 788–793. San Francisco, CA: IEEE.
Publisher's VersionAbstractPower constrained designs are becoming increasingly sensitive to supply voltage noise. We propose a hardware-software collaborative approach to enable aggressive operating margins: a checkpoint-recovery mechanism corrects margin violations, while a run-time software layer reschedules the program's instruction stream to prevent recurring margin crossings at the same program location. The run-time layer removes 60% of these events with minimal overhead, thereby significantly improving overall performance.
Software-assisted hardware reliability: abstracting circuit-level challenges to the software stack Vijay Reddi, Meeta Gupta, Michael Smith, Gu Wei, David Brooks, and Simone Campanoni. 7/26/2009. “
Software-assisted hardware reliability: abstracting circuit-level challenges to the software stack.” In Proceedings of the 46th Annual Design Automation Conference, Pp. 788–793. San Francisco, CA.
Publisher's VersionAbstractPower constrained designs are becoming increasingly sensitive to supply voltage noise. We propose a hardware-software collaborative approach to enable aggressive operating margins: a checkpoint-recovery mechanism corrects margin violations, while a run-time software layer reschedules the program's instruction stream to prevent recurring margin crossings at the same program location. The run-time layer removes 60% of these events with minimal overhead, thereby significantly improving overall performance.
Software-assisted hardware reliability: abstracting circuit-level challenges to the software stack Hayun Chung, Alexander Rylyakov, Toprak Deniz, John Bulzacchelli, Gu Wei, and Friedman Daniel. 6/16/2009. “
A 7.5-GS/s 3.8-ENOB 52-mW flash ADC with clock duty cycle control in 65nm CMOS.” In 2009 Symposium on VLSI Circuits, Pp. 268–269. Kyoto, Japan: IEEE.
Publisher's VersionAbstract
A 7.5-GS/s 4.5-bit analog-to-digital converter (ADC) in 65nm CMOS is presented. A two-stage track-and-hold (TAH) with clock duty cycle control reduces bandwidth requirements on the slow TAH output to enable high sampling rates with low power consumption. The 7.5-GS/s flash ADC consumes 52-mW and occupies 0.01-mm 2 . Clock duty cycle control improves ENOB from 3.5 to 3.8 with an input sinusoid at the Nyquist frequency.
Krishna Rangan, Gu Wei, and David Brooks. 6/2009. “
Thread motion: fine-grained power management for multi-core systems.” In ACM SIGARCH Computer Architecture News, 3rd ed., 37: Pp. 302–313. ACM.
Publisher's VersionAbstract
Dynamic voltage and frequency scaling (DVFS) is a commonly-used power-management scheme that dynamically adjusts power and performance to the time-varying needs of running programs. Unfortunately, conventional DVFS, relying on off-chip regulators, faces limitations in terms of temporal granularity and high costs when considered for future multi-core systems. To overcome these challenges, this paper presents thread motion (TM), a fine-grained power-management scheme for chip multiprocessors (CMPs). Instead of incurring the high cost of changing the voltage and frequency of different cores, TM enables rapid movement of threads to adapt the time-varying computing needs of running applications to a mixture of cores with fixed but different power/performance levels. Results show that for the same power budget, two voltage/frequency levels are sufficient to provide performance gains commensurate to idealized scenarios using per-core voltage control. Thread motion extends workload-based power management into the nanosecond realm and, for a given power budget, provides up to 20% better performance than coarse-grained DVFS.
{kind=link}