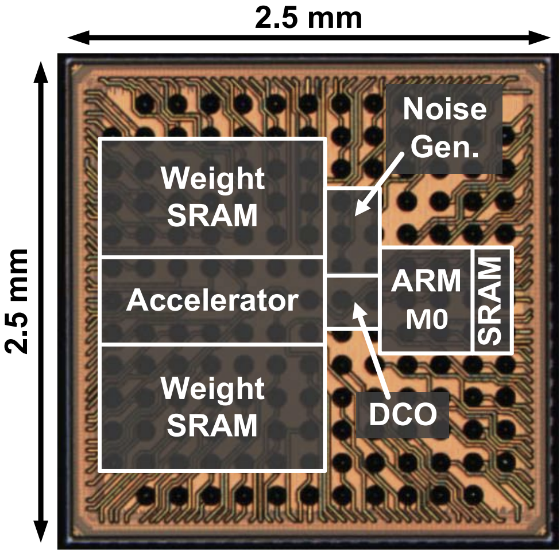
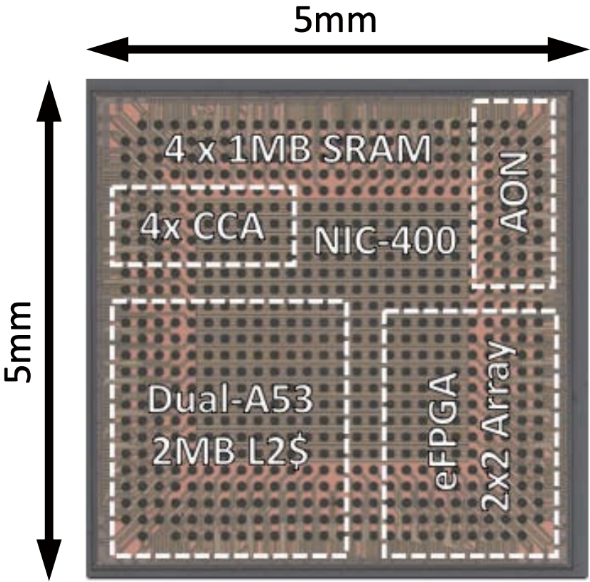
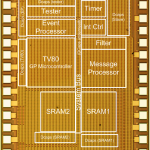
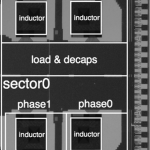
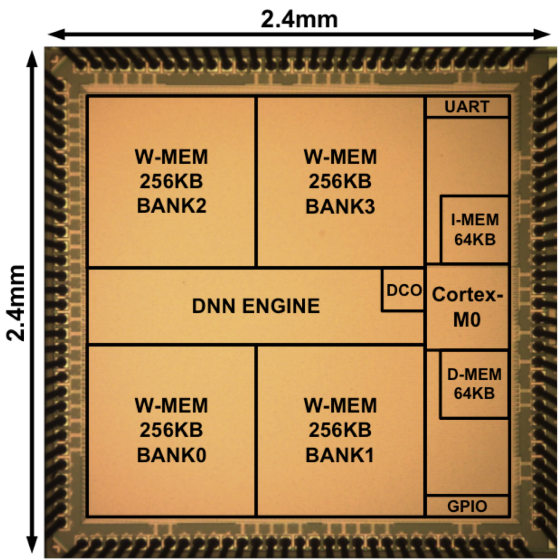
Chip prototyping provides several important benefits for our research. Silicon implementation provides the opportunity to learn about power and variability issues with real measurements in ways that simulations alone cannot provide, and our chip prototypes allow us to more convincingly demonstrate the benefits of our proposed approaches. In addition, the design process instills an appreciation of complexity, testing, and validation issues encountered when creating real hardware. Our group has designed prototype chips for several projects.
We thank IBM, TSMC, SRC, and UMC for fabrication support for these projects.